




AI Deployment: A Cambrian Explosion

AI has been in an ever-expanding renaissance for the past decade, with the success of AlexNet being a pivotal moment that sparked a new wave of deep learning research in 2012. Since then, there have been several step-change moments, such as the success of reinforcement learning algorithms on Atari games by DeepMind in 2013, AlphaGo beating the Go world champion in 2016, and the introduction of transformers in 2017, outperforming LSTMs on language modeling tasks. As far as public impact goes, the release of ChatGPT in 2022 is certainly the biggest moment. Suddenly, people with no prior AI experience were able to witness and leverage the remarkable power of large language models (LLMs) for the first time. Beyond LLMs, AI continues to expand into all kinds of areas, and there is no sign that this will slow down.
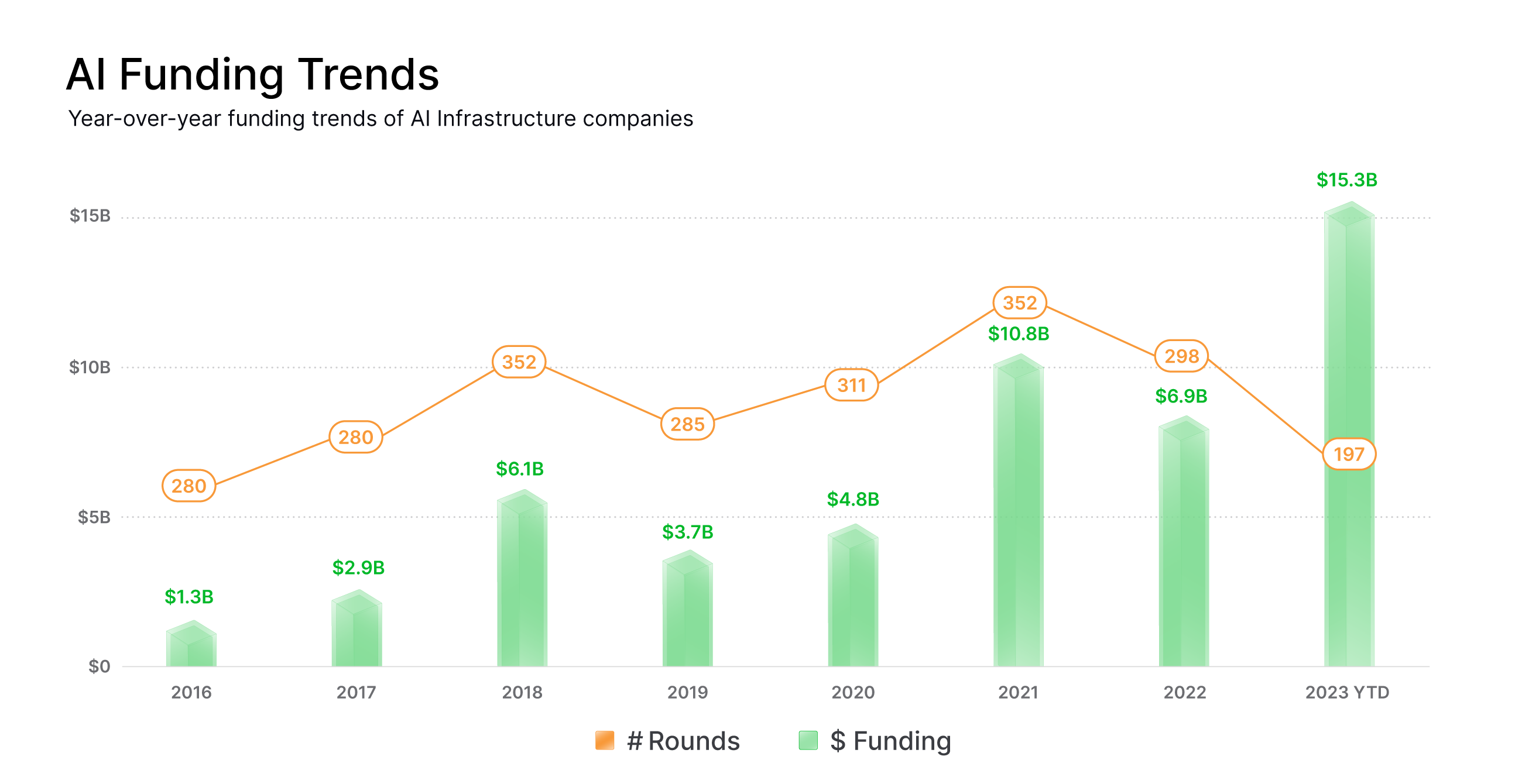
Training models for research purposes and deploying them in production are two very different worlds, and the latter has grown considerably as AI has increasingly left the research lab and entered industry. Naturally, as commercial interest has grown, huge innovation has occurred at all levels of the deployment stack, and this has corresponded to an increase in venture funding for AI infrastructure companies, as shown below. This is a great thing, but the problem is that these innovations do not all occur in harmony, and the general tendency and temptation is for builders to strive to be the solution, rather than a part of the solution. In reality, most tools excel at specific niches, whilst being okay when applied in other domains outside of their niche. However, the tendency is for tools to overstate their generality and applicability, and this dilutes the messaging and adds to the noise and confusion felt by engineers operating in the space. All of this means that it’s very challenging to know where to start when deploying models in an optimal manner for your specific use case.
This sentiment has been echoed by many of the engineers we work with, who find it overwhelming trying to keep up with so many deployment tools constantly popping up. Motivated by this confusion felt by many, we’ve decided to create a series of blog posts which give an overall “lay of the land” as far as deployment tooling goes, whilst striving to do this in a fully fair and impartial manner. Our central goal is to empower builders who are looking to deploy their models in production, so they know how to think about the problem in a systematic and pragmatic manner, with full knowledge of all the amazing tools, and how and when each one should be leveraged.
The Deployment Stack
As outlined above, there is an incredibly rich stack of tools for deploying models in production, each of which must interact harmoniously with one another. Despite the complexities of the stack, most end users generally only care about a handful of competing metrics: model accuracy, server uptime, setup simplicity, server scalability, running costs, and latency. Many of these metrics are in direct competition. For example, running costs can be driven down by using dynamic batching on a smaller number of devices, but this can increase the latency. Running costs and latency can also both be driven down by leveraging model compression, but this comes at the expense of model accuracy. Cost can also be driven down by using cheaper and older hardware, but this also generally comes at the expense of increased latency. We present a very high-level overview of some of these competing factors in the table below.

For any given application, whether or not it is explicitly acknowledged or understood, there is always a predefined importance assigned to each of these competing factors, and finding the optimal configuration which perfectly balances these competing factors for the application is a very complex challenge.
As far as the deployment stack goes, we will unpack deeper nuances in future posts, but for now, it is sufficient to consider this stack for deploying a given model as having four distinct layers: the serving layer, model compression techniques, the compiler, and the hardware. We will consider each of these in turn.

The Serving Layer
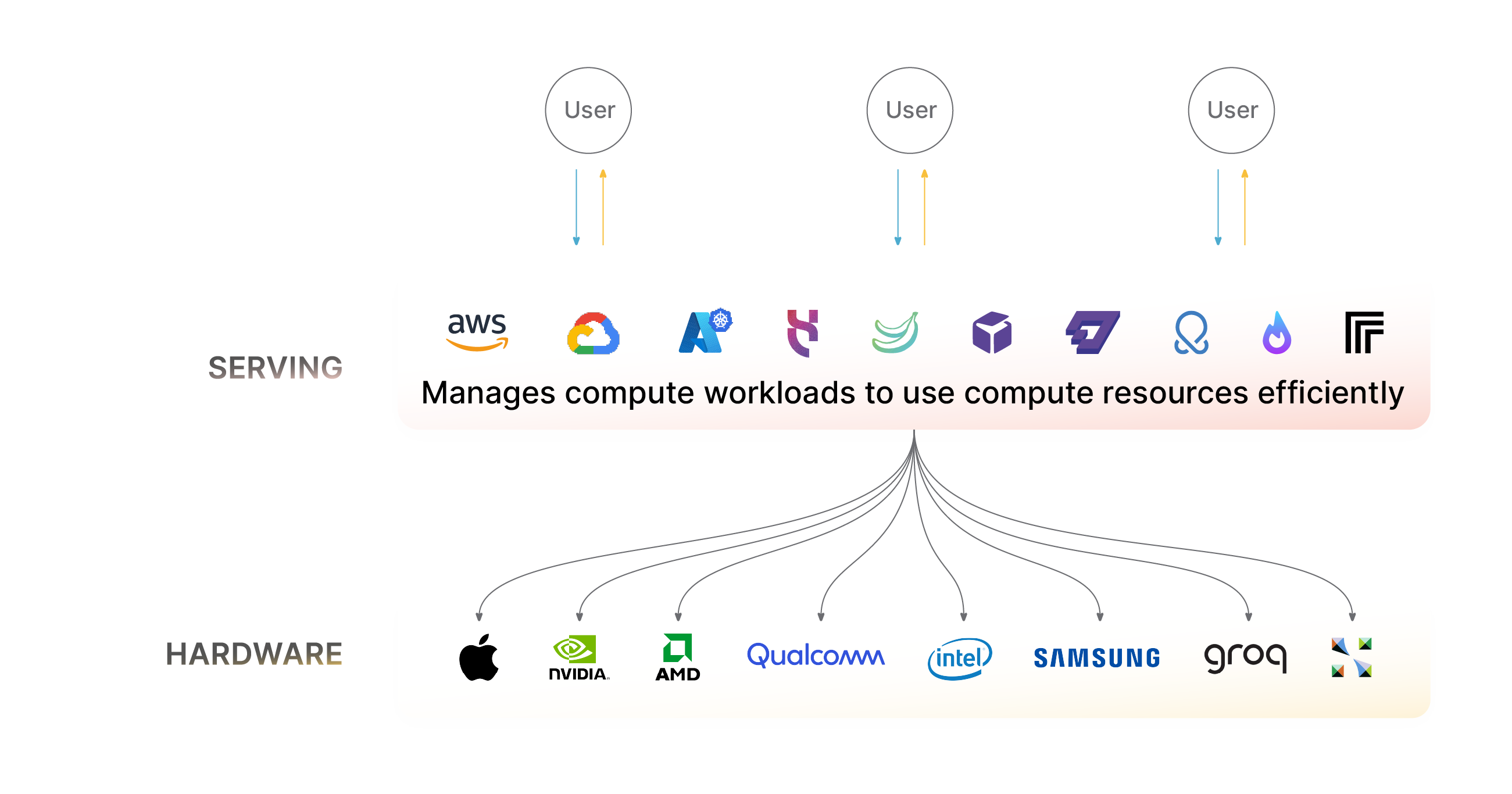
The serving layer receives API requests and returns API responses. In order to achieve this goal, under the hood the serving layer may need to scale up and scale down instances of the underlying model in order to meet the API request demands, and ideally, this should be done in a cost-effective manner. This means not having model instances lying dormant consuming cloud costs, and it often also means potentially dynamically batching requests such that several requests from different users can be executed during a single model forward pass, on the same device, saving on cost and compute at the expense of latency. The extent to which latency and cost can be traded off depends heavily on the application. Meeting user demand but also not over-provisioning hardware is also a delicate balance. For maximal end-user reliability, it is likely necessary to over-provision hardware, with some lying dormant with wasted costs. Serverless options avoid this problem, but without a dedicated device, you can’t always guarantee access to the hardware you need as demand changes, which affects the uptime and reliability of your application, with huge latencies possible when new devices need to be provisioned dynamically. All of this culminates in a complex optimization problem which the serving layer is responsible for managing. We will soon be publishing a separate post dedicated to this part of the stack. Suffice it to say, decisions on what tooling to use are highly non-trivial, and depend heavily on the application and the metrics of importance.
Model Compression
The model is the actual network architecture, weight matrices, and numeric representations that underpin these weights. While most models use dense weight matrices and floating point 32 representations during training, there are a variety of techniques to compress the model for faster inference and lower memory consumption, typically at the expense of model accuracy. For example, using iterative pruning, Intel researchers achieved a 90% sparsity ratio in compressing BERT-Large with one 1% drop in accuracy, as detailed in "2111.05754 Prune Once for All: Sparse Pre-Trained Language Models". The same is true for quantization, where the memory intensive float-32 weights are substituted with more space efficient alternatives, like 8, 4, or even 2-bit representations( 2106.08295: A White Paper on Neural Network Quantization) . This substitution results in compression ratios of 4x, 8x, or even 16x respectively. Tensorization is another technique, whereby the large weights are replaced with much smaller lower rank tensors using tensor decomposition methods( 2304.13539: Tensor Decomposition for Model Reduction in Neural Networks: A Review), leading to a reduction in arithmetic intensity as well as lower memory requirements. For example, researchers from Moscow State University were able to achieve 80x compression with VGG network with only a 1.1% drop in accuracy on the CIFAR-10 dataset(1611.03214: Ultimate tensorization: compressing convolutional and FC layers alike). These techniques are generally orthogonal to one another, meaning that combinatorial applications can compound to bring even stronger compression rates ( 2208.09684: Combining Compressions for Multiplicative Size Scaling on Natural Language Tasks). Model distillation is another technique, whereby a smaller model is trained on the outputs of a larger model, which distills more information into the smaller model than can be achieved via supervised training alone (2006.05525:Knowledge Distillation: A Survey). Model compression is especially helpful when deploying models on the edge, or when the task is sufficiently simple such that lower accuracies can be tolerated. We will soon be publishing a separate post dedicated to this part of the stack. Suffice it to say, decisions on what compression techniques to apply are highly non-trivial, and depend heavily on the application and the metrics of importance.

The Compiler
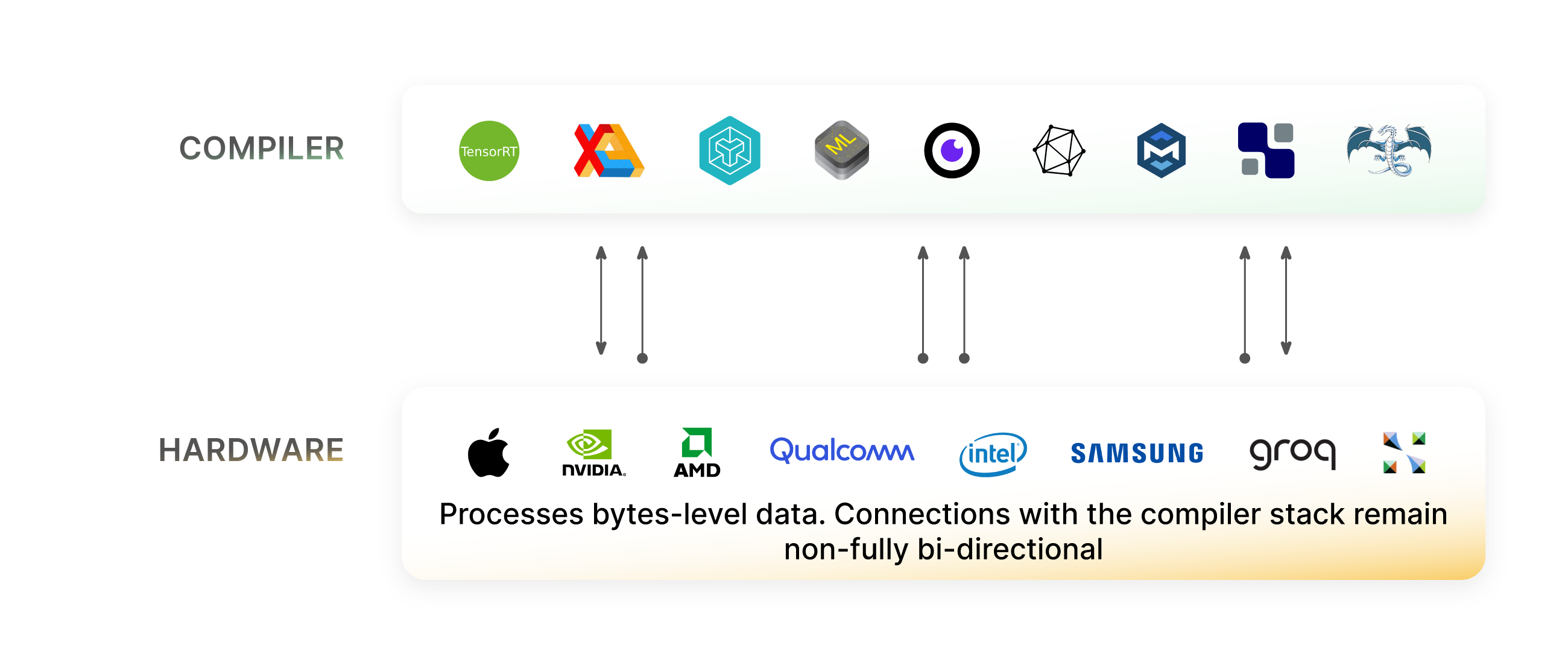
With the mathematics of the model defined, the next step is to compile this into an efficient low-level representation, which the selected hardware is able to understand. There are a variety of ML-specific compilers, APIs and compiler tools that have emerged, and finding the optimal combination of these tools is again highly non-trivial. ML models can generally be expressed as a static mathematical directed-acyclic-graph (DAG), and this makes them somewhat easier to compile than arbitrary programming languages, which can exhibit a much broader set of behaviors. The process of compiling an ML model is one of progressive lowering, to lower and lower level representations. At each level, optimization passes can be applied which, for example, fuse operations together, remove redundant nodes, and cache repeated computation. There are a variety of compiler tools which operate at various levels of this progressive lowering process, and some of these tools are vendor-agnostic, whilst others are vendor-specific. We will Keep the definition of a “compiler tool” very broad for now, but we will unpack the deeper details and nuances in a later post dedicated to compiler infrastructure. The ecosystem of compiler tools include: (a) vendor-specific low-level languages such as CUDA, ROCm, and various assembly languages (b) higher-level representations for expressing ML models such as OpenVINO, ONNX, TensorRT, and TinyGrad, (c) infrastructure for writing new compilers in a systematic manner, such as LLVM and MLIR, and (d) flexible compilers for automatically finding optimal configurations during graph lowering, such as ApacheTVM, OpenAI/Triton, XLA and Mojo. As mentioned above, we will soon be publishing a separate post dedicated to this part of the stack. Suffice it to say, decisions on what compiler tools to use is a highly non-trivial decision, and it depends heavily on the application and the metrics of importance.

The Hardware
Finally, we have the hardware that actually processes the 1s and 0s under the hood. Over the past few years, several new hardware vendors and several established vendors have released chips for AI training and deployment, challenging Nvidia’s position as the only real player in town for AI. Examples of new companies include: Groq, SambaNova Systems and Tenstorrent. Examples of established companies releasing competitive chips include Google, AMD and Intel. Many of these vendors have raw performance which is competitive with Nvidia’s AI chips, but one of the biggest barriers to entering the market is the sophistication of the software stack, and how well this hardware works “out-the-box” with ML frameworks like PyTorch, TensorFlow and JAX. New vendors need to decide what compiler infrastructure to optimize for, and this is a non-trivial decision. One option is to integrate with existing high-level compiler infrastructure such as ApacheTVM, OpenVINO, XLA, the ONNX Runtime or OpenAI Triton. Another option is to create a custom MLIR dialect and build out a custom compiler in isolation from the established high-level infrastructure. Either way, the important end goal is to integrate natively with the ML frameworks such as TensorFlow, PyTorch and JAX, and integrating with the high-level compiler backends that these already support is generally the favorable option, and this is the approach most new vendors are taking in order to move quickly. Aside from dedicated high-throughput AI chips, another important class of devices are edge devices, where AI models must often run as part of broader user applications, in order to keep server-side compute costs down, and to minimize latency for the user. We will soon be publishing a separate post dedicated to this part of the stack. Suffice it to say, deciding what device (or combination of devices) to use is a highly non-trivial decision, and it depends heavily on the application and the metrics of importance.
Optimal Deployment Recipes
In the previous four paragraphs, we have briefly explored the complexities involved in deciding what tools and techniques to use at each level of the stack in isolation. Thinking about these in isolation is clearly already challenging enough, but unfortunately the complexities compound significantly when considering all levels of the stack simultaneously. The intricate co-dependence between all layers in the stack makes it ever more difficult to reason about the optimal configuration for any given deployment problem.
For example, some compression techniques cannot be exploited by certain compilers or hardware. BitsAndBytes is CUDA-specific for example, which means it only supports Nvidia GPUs. In the case of pruning, you might be able to remove 90% of the values from a weight matrix, but that’s not helpful if your device has no mechanism to exploit this sparsity for improved runtime, and still performs the matrix multiplications densely, as is the case for most GPU devices. Similarly, the extent of compression you’re able to achieve changes the memory footprint of your model, and thus directly affects batch size you’re able to fit onto the same device, which impacts your dynamic batching strategy at the serving layer. This will also modify the extent to which tools like Kubernetes are needed for multi-node orchestration, and the hyperparameters selected. Certain compilers are also especially well suited for certain hardware targets, and the combinatorial search space of all compilers and hardware is enormous. All of this is to say, getting the most out of your deployment configuration is an incredibly complex problem with an unimaginably large search space, and huge opportunities for performance gains are inevitably being left unrealized with suboptimal off-the-shelf deployment configurations.
In the next few posts, we will be unpacking this problem in much more detail, and outlining how we’re working to tackle this deep fragmentation problem, and unlocking optimal deployment configurations for the benefit of everyone looking to deploy AI models at scale.
More Reads










Wish Your LLM Deployment Was
Faster, Cheaper and Simpler?
Use the Unify API to send your prompts to the best LLM endpoints and get your LLM applications flying