




Model Pruning: Keeping the Essentials

In the previous blog post of our model compression series we went over the available quantization libraries and their features. In a similar fashion, we will now go over the packages and tools that enable us to apply different kinds of pruning methods (which we introduced in the introduction post of the model compression series) on our machine learning models.
As a short reminder, Pruning is a model compression technique that involves removing the unnecessary connections or weights from deep neural networks. The goal of pruning is to obtain a sparse model with lower model size but similar accuracy. Pruning can be done in different ways, such as removing the smallest weights, or removing the weights that have the least impact on the output of the network model.
In this blog post, we’ll dive into pruning libraries to outline their unique features algorithms. We conclude the post with some tips on how to choose the best tool depending on your situation.
What are The Different Pruning Tools Available ?
PyTorch natively supports structured, unstructured, global, local as well as iterative pruning and one-shot pruning. It also supports some out-of-the-box pruning algorithms that can be used locally as well as globally, in an iterative fashion or in one-shot manner. Natively supported pruning algorithms include:
- Random Unstructured Pruning which performs weight pruning randomly on a certain percentage of weights in the model. The basic idea behind this method is to randomly remove some weights or connections from the network, effectively "pruning" it. This results in a smaller, more efficient model that requires fewer computations and less memory to run.
- Random Structured Pruning which performs channel pruning randomly on a certain percentage of channels in the model. In contrast to random unstructured pruning, which removes individual weights or connections at random, random structured pruning aims to remove complete structures within the network, such as whole neurons, channels, or filters.
- Ln Structured Pruning which performs channel pruning on a percentage of channels based on their Ln norm. Ln norm is a measure of the absolute value of a vector raised to the n-th power.
- L1 Unstructured Pruning which performs weight pruning on a percentage of weights that have the lowest L1 norm. L1 norm structured pruning uses the sum of the absolute values of a vector's components as the basis for determining the importance of structures within a neural network.
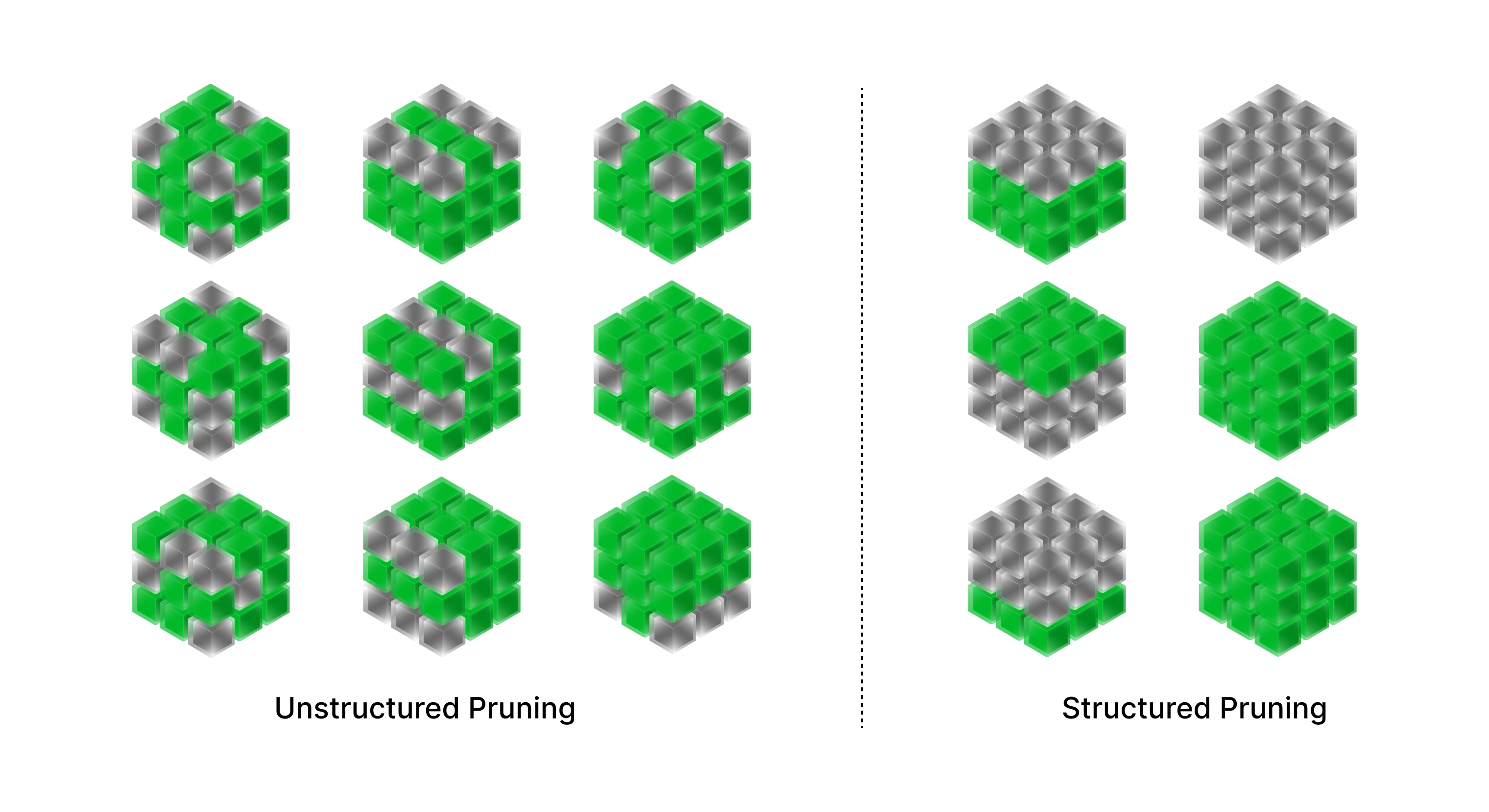
While Pytorch’s pruning API is constantly improving with new features like semi-structured sparsity (a data layout first introduced in Nvidia’s Ampere architecture), there are a host of libraries that implement their own pruning APIs.
These libraries generally either (a) provide a unified API which can be used across multiple frameworks and hardware backends, or (b) implement a new pruning algorithm. Let’s look into a few libraries like these in detail.
SparseML
SparseML is an open source library developed and maintained by Neural Magic for applying compression recipes to neural networks. Currently, it supports pruning, quantization and knowledge distillation for compressing vision, NLP, and now, large language models as well.
SparseML provides pre-compressed deep learning models in their SparseZoo that uses SOTA pruning algorithms including:
- Gradual Magnitude Pruning (GMP) algorithm which is an iterative unstructured pruning algorithm that removes weights closest to zero during the training process before retraining the model to fine-tune the weights of the remaining connections
- Alternating Compressed/DeCompressed (AC/DC) pruning method where sparse and dense models are co-trained to recover the dense baseline accuracy through fine-tuning
- Optimal BERT Surgeon (oBERT) which extends existing work on unstructured second-order pruning by allowing for pruning blocks of weights
- SparseGPT, a one-shot pruning method for LLMs, which relies on Hessian inverses to incrementally prune the columns of the weight matrix while concurrently updating the weights to the right of the column being processed.
In addition to sparsity, their pre-compressed models are quantized as well to reduce memory requirements and gain additional speed up, referred to as Compound Sparsity by Neural Magic.
SparseML provides a simple and intuitive API for fine-tuning these pre-compressed models to their custom datasets with recipes that are able to maintain the same sparsity level during the fine-tuning process, a concept they call sparse-transfer.
Results vary from one pruning technique to another with AC/DC pruning claimed to achieve upto 90% sparsity with resnet-50 model whilst retaining 99% of the baseline accuracy, 90% sparsity whilst recovering 99% of the baseline accuracy with oBERT, and 50% sparsity on OPT-175B with as little as 0.13 decrease in perplexity using SparseGPT.
AI Model Efficiency Toolkit (AIMET)
Besides the quantization features we discussed in the previous section, AIMET also provides a standardised workflow for pruning models.
AIMET’s pruning pipeline typically starts with determining the target compression ratio which can be done either using Greedy Compression Ratio Selection where individual layers of the original machine learning model are analysed to determine optimal compression ratios per layer, or Manual Compression Ratio Selection where the user can manually specify the ratio. The second phase consists in applying the desired compression algorithm.
Currently, AIMET mainly supports Channel Pruning which is a pruning technique that reduces less-important input channels from layers in a given model. Channel Pruning is based on the following steps:
- Channel Selection: For a given layer and compression ratio Channel Selection analyses the magnitude of each input channel (based on the kernel weights for that channel) and chooses the channels with the least magnitude to be pruned. Channel selection can be based on various metrics methods like Taylor Expansion, L1-norm, Gradient-based methods, etc.
- Winnowing: Winnowing removes the identified input channels (through Channel Selection) from the target module. Output channels of previous modules are also modified accordingly. The winnowing process typically involves analyzing the importance scores assigned to each feature by the model, either through methods like sensitivity analysis or feature selection algorithms. Features with low importance scores are then removed, and the model is retrained on the reduced set of features.
- Weight and Bias Reconstruction: After identifying and removing less important channels during channel pruning, there might be a decrease in model accuracy due to the sudden reduction in capacity. To mitigate this issue, AIMET will adjust the weight and bias parameters of any pruned layer to try and match the outputs of that layer and closely match the outputs prior to pruning.
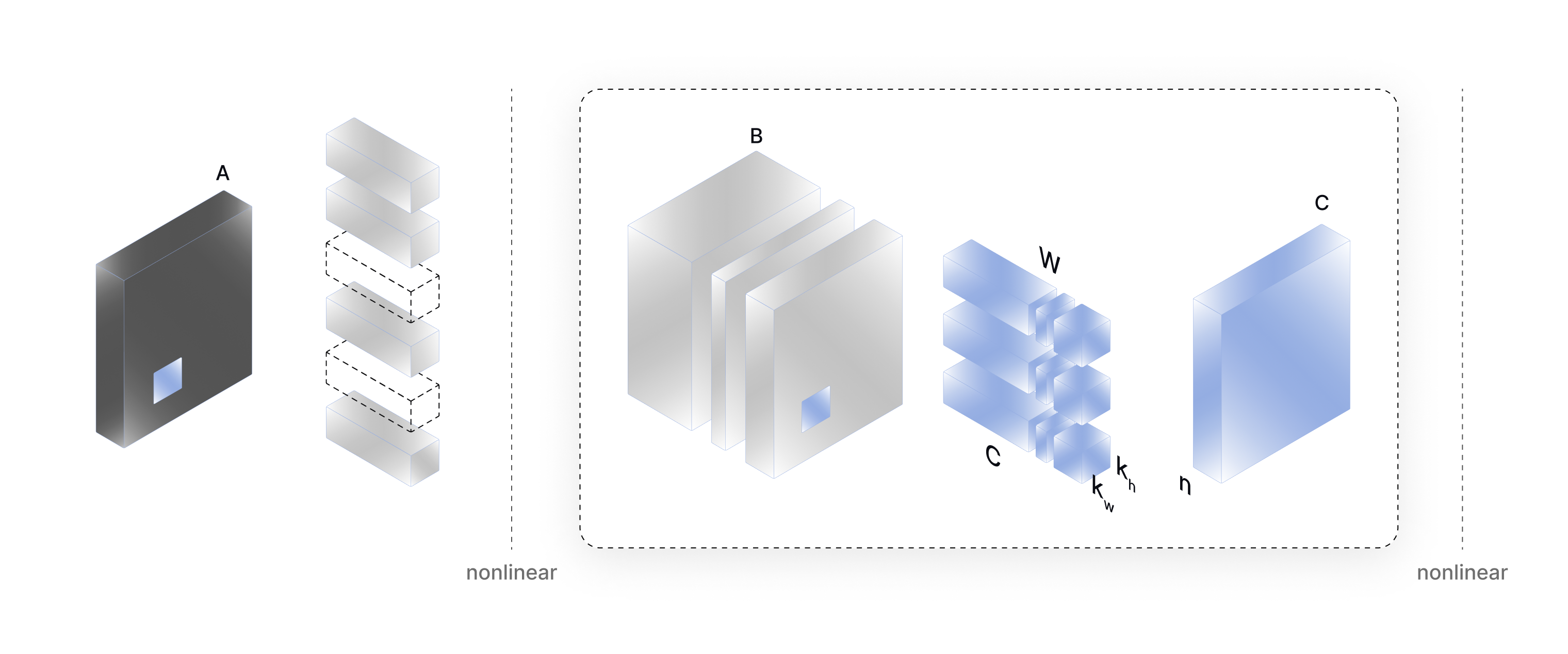
Compression results can then be further improved through rank rounding which tries to match the multiplicity level that works best with the user’s device, or per-layer fine-tuning which applies a custom user-defined fine-tuning function layer-wise during the compression step.
Intel Neural Compressor
In addition to quantization, Intel Neural Compressor (INC) also provides a unified API for pruning an artificial neural network. INC supports multiple pruning algorithms including:
- NxM pruning where consecutive NxM matrix blocks are used as the minimum unit for pruning and N:M pruning wherein out of every M consecutive weights N are selected for pruning.
- Unstructured Pruning and Structured / Unstructured Channel Pruning. For such algorithms, INC supports different criteria for pruning such as magnitude, gradient, and snip momentum.
In addition to these basic pruning strategies, INC also supports SOTA pruning techniques specifically designed for LLMs such as SparseGPT which we discussed above, and Retrain-free which removes the need to retrain a model to apply pruning, and preserves the model’s accuracy by algorithmically targeting the heads and filter to prune based on Fisher information.
Notably, Retrain-free pruning achieves a 20% sparsity per layer while preserving accuracy with an accuracy loss of less than 1%
Neural Network Intelligence
Just like with quantization, Neural Network Intelligence (NNI) supports a variety of pruning algorithms, each with its unique characteristics and use case.
- The Level Pruner prunes based on the absolute value of each weight element.
- The L1 Norm Pruner and L2 Norm Pruner prune output channels with the smallest L1 and L2 norm of weights, respectively.
- The FPGM Pruner is based on the geometric median for deep convolutional neural network acceleration.
- The Slim Pruner prunes output channels by pruning scaling factors in BN layers, aiming for efficient convolutional networks.
- The Taylor FO Weight Pruner prunes filters based on the first order Taylor expansion on weights, estimating the importance for neural network pruning.
- The Linear Pruner increases sparsity ratio linearly during each pruning round, using a basic pruner to prune the model.
- Finally, the AGP Pruner implements automated gradual pruning, and the Movement Pruner adapts sparsity by fine-tuning.
Which Pruning Tool is Best for You?
If there already exists a pre-compressed version of the model you are interested in Neural Magic’s SparseZoo, you could save a lot of time and resources by sparse-fine-tuning this model on your data-set using the recipes in Sparse ML. If you’re interested in deploying the model on CPU, SparseML can also be used to export the model to ONNX and then deploy it on Neural Magic’s Sparsity Aware deployment engine DeepSparse. If you’re interested in GPU deployment, you should look into ApacheTVM or TensorRT.
If the target platform you want to deploy the model to doesn’t support unstructured sparsity, you can use the tools discussed above to perform structured pruning on the model. You could experiment with AIMET’s Greedy Compression Ratio Selection and Channel Selection discussed above to get an idea of the optimal compression ratios for each layer and the most optimal channels for pruning and then you can experiment with different structured pruning techniques offered by these libraries.
In the case of pruning, it’s often best to do some research yourself to find out if the architecture that you are working with has already been researched for pruning and then try to reproduce the results with your model using these tools.
Conclusion
This concludes our tour of pruning tools and techniques. While not as broad as quantization, pruning tools and libraries offer distinct sets of features and algorithms that work best with different deep learning models.
Finding the best algorithm requires careful analysis of the target model architecture and its behavior. This also often involves trial-and-error and relying on heuristics to exercise judgement when selecting an algorithm to use.
We hope this post helped you get a high level understanding of which tools are best to be used in which scenarios! Stay tuned for the next post of our model compression series!
More Reads










Wish Your LLM Deployment Was
Faster, Cheaper and Simpler?
Use the Unify API to send your prompts to the best LLM endpoints and get your LLM applications flying