




Quantization: A Bit Can Go a Long Way

Following up with our model compression blog post series, we will now delve into quantization, one of the more powerful compression techniques that we can leverage to reduce the size and memory footprint of our models.
Going forward, we will assume that you have read the first blog post of the series, where we introduced the concept of quantization. Building on top of this introduction, we will go over the different tools and libraries that can help us when quantizing a model. Given the importance of the field, we will also talk in more detail about quantization in large language models, and lastly, we will discuss which of these tools and techniques should be used depending on the use case.
What are The Different Quantization Tools Available?
PyTorch natively supports both Post-Training quantization and Quantization-Aware training. Specifically, PyTorch’s API lets you apply dynamic post training quantization which involves converting the weights (offline) and activations ( on the fly) to int8 before doing the computation, static post training quantization where a calibration dataset is utilised to compute the distributions of activations which can be used to quantize the activations during inference, and static quantization-aware training where the weights and activations are “fake quantized” during to emulate inference time behaviour which allows the model to adapt to the precision loss introduced by quantization.
Each of these techniques can be used either on eager mode where the user needs to specify where quantization and dequantization happens manually, or FX Graph Mode Quantization which improves upon Eager Mode Quantization by adding support for functionals and automating the quantization process, but might require refactoring the model to make it compatible with symbolic tracing.
The following table gives an overview of each approach and related considerations:
Pytorch’s Quantization Support Matrix. Source: Quantization — PyTorch 2.1 documentation
Using PyTorch’s built-in quantization, you can expect to achieve a 4x reduction in model size and an average speedup of 2x to 3x compared to floating point implementations depending on the hardware platform and the model being benchmarked.
PyTorch's native support for quantization is expected to continually improve and evolve over time. This means users can expect even better capabilities and features for quantization natively supported by PyTorch in the future. In that sense, it only makes sense that libraries like Neural Magic’s SparseML and MosaicML's Composer have built their quantization features directly on top of PyTorch's quantization module. These libraries provide further tools and functionalities to enhance the quantization process and make the process more efficient and user-friendly.
While PyTorch’s internal compression features are set to expand, they remain somewhat limited as of now. As such, there are a host of open-source libraries that implement their own quantization modules and complement PyTorch’s built-ins with unique features.
Neural Compressor
Intel Neural Compressor’s quantization module offers a unified scikit-learn-like API for various frameworks and backend libraries. It includes a fit method that quantizes the model using a quantization configuration. If the framework natively supports quantization (such as PyTorch and TensorFlow), the module builds on top of its quantization features. Otherwise, it implements the support from scratch. Intel’s Neural Compressor supports post training dynamic quantization, post training static quantization as well as quantization aware training for a wide range of frameworks and backend libraries.
On top of the unified API, Neural Compressor introduces unique algorithms and quantization approaches, including Accuracy Aware Tuning which creates a tuning space by querying the framework quantization capabilities and the model structure to automatically select the optimal ops to be quantized by the tuning strategy based on a pre-defined accuracy metric, High customizable configurations through quantization recipes and custom definition of operator name and types, Both Weight Only (AWQ, GPTQ, TEQ, RTN) and Weight + Activation quantization algorithms for LLMs as well as an improved version of SmoothQuant with a smoothing factor auto-tuning algorithm achieving 5.4 % and 1.6% higher accuracy over default SmoothQuant (we’ll discuss SmoothQuant in the sub-section on LLM quantization below).
On Intel 3rd Gen Intel® Xeon® Scalable Processors, users could expect up to 4x theoretical performance speedup and even further performance improvement with Intel® Advanced Matrix Extensions on 4th Gen Intel® Xeon® Scalable Processors.
Model Compression Toolkit (MCT)
SONY’s Model Compression Toolkit is another model compression tool that focuses on quantization and comes with a suite of features that make it easier to optimise neural networks for efficient deployment, including synthetic image data generation and visualisation tools.
MCT supports various quantization schemes including Power-Of-Two quantization which quantizes values to the nearest power of two and is particularly friendly for hardware implementations given the efficiency of binary representations, Symmetric quantization which distributes quantization levels symmetrically on both sides of zero and is useful for maintaining signed values while reducing bit precision, and Uniform quantization values are uniformly distributed within equal intervals for simplicity.
Besides offering QAT and GPTQ, MCT improves upon PTQ by introducing Enhanced Post Training Quantization (EPTQ) which removes the necessity of manually selecting the layers on which quantization is performed. The approach is based on computing the trace of the Hessian Matrix for the task loss which is used to determine the most sensitive layers for optimization.
AI Model Efficiency Toolkit (AIMET)
AIMET is a model compression software toolkit developed by Qualcomm AI Research group that also builds on top of quantization features offered natively by Pytorch and provides a unique set of algorithms as well as an easy to use-API for compressing neural networks. It supports both Post-Training Quantization as well as Quantization Aware Training.
AIMET also provides several unique features including:
1. An Autotuning Quantization API: which analyses the model and applies the supported Post Training Quantization Techniques in a best-effort manner until the model meets the evaluation goal.
2. Unique PTQ Optimization algorithms: including Batchnorm Folding which merges layers following batch norm layers into one layer with different weights, Cross-Layer-Equalization which exploits the scaling equivariance in neural networks to equalise the ranges of each channel in a model to maximise precision per channel and Adaround which improves the results from naive nearest-rounding by optimising the rounding approach to minimise the divergence from actual weights using a novel approach based on (a) using a rectified sigmoid function for clipping that doesn’t suffer from vanishing gradients, and (b) introducing a regularisation parameter to the optimization function to encourage convergence to either of the binary results.
3. Unique QAT optimization algorithms: With support for both QAT with Range Learning where encoding values for activation quantizers are initially set during the calibration step but are free to update during training, allowing a more optimal set of scale/offset quantization parameters to be found as training takes place, and QAT without Range Learning where encoding values for activation quantizers are found once in the beginning during the calibration step after a quantization simulation has been instantiated, and are not updated again subsequently throughout training.
4. A Customizable Quantization Workflow: AIMET includes features like QuantAnalyzer which determines the most sensitive layers to quantization by performing per layer sensitivity and MSE Analysis, SimQuant which can simulate the effects of quantized hardware allowing the user to apply post-training and/or fine-tuning techniques in AIMET to recover loss in accuracy and BiasCorrection which can used to correct for biassed error introduced by quantization in the activations.
Neural Network Intelligence (NNI)
Microsoft’s Neural Network Intelligence (NNI) supports a variety of unique quantization algorithms. The QAT Quantizer provides efficient integer-arithmetic-only inference. The DoReFa Quantizer is used for training low bitwidth convolutional neural networks with low bitwidth gradients. The BNN Quantizer is used for training deep neural networks with weights and activations constrained to +1 or -1. The LSQ Quantizer is based on the learned step size quantization method. Lastly, the PTQ Quantizer is used for post-training quantization, collecting quantization information during calibration with observers. Each of these quantizers has its own unique characteristics and use cases, and they can be used in combination to achieve more efficient model compression.
On Large Language Models Quantization
Before wrapping up this section on quantization, we’d like to take some time to discuss Large Language Models (LLMs) specific quantization tools and approaches. There are a number of tools and techniques that have been developed exclusively for LLMs in order to quantize them into even lower bit-widths (e.g. 4 bits, 3 bits, 2 bits).
Most of these techniques are post training quantization techniques because:
(a) It is extremely expensive to train/fine-tune LLMs with hundreds of billions of parameters. For instance, GPT175B demands a minimum of 320GB of storage in FP16, this means you need at least 5 A100 GPUs, each featuring 80GB of memory to train/fine-tune it
(b) Quality data for training/fine-tuning is hard to find. The sheer scale and diversity of pre-training data is itself an obstacle. Pre-processing might be prohibitive, or worse, some data might simply not be available due to legal restrictions. It is also increasingly common to train LLMs in multiple stages, involving instruction tuning and reinforcement learning
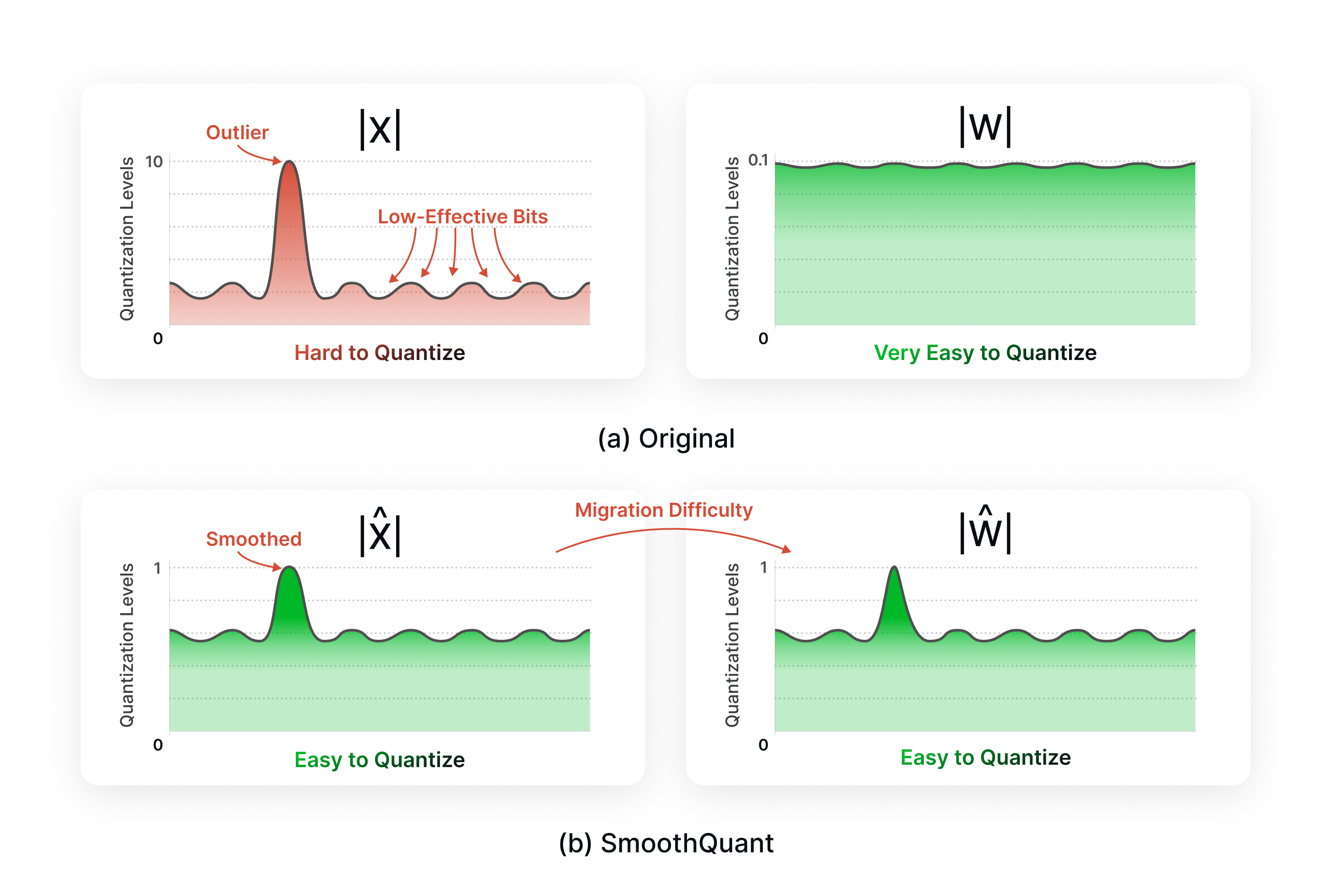
Moreover, it should be noted that traditional quantization schemes (such as int8 affine or symmetric quantization) generally do not work well on LLMs, often resulting in significant accuracy degradation. One reason for this is that activations in LLMs contain a large number of outliers, as shown in the below figure. As a result, there are many techniques that focus only on quantizing the weights (e.g. AWQ, GPTQ, BitsandBytes). However, there are also techniques like SmoothQuant which provides a way to smoothen the activations so that it is easier to quantize them.
Which Quantization Tool is Best for You?
It can be quite overwhelming to go through all of these tools and figure out which one works best for your use case. In the following passage we will provide some general guidelines on which tools to explore depending on your use-case and constraints.
If you have the resources to train the model and have strict accuracy requirements: You could look into quantization-aware-training.
- Depending on your level of expertise: If you have enough time for experimenting, a good starting point for you could be to look into AIMET’s QuantAnalyzer discussed above to manually find the quantization sensitive layers in your model, you can then experiment with different quantization schemes such as the quantization granularity, symmetric or affine quantization, pytorch fx or eager modes QAT, AIMET’s QAT with and without range learning, or NNI’s quantization algorithms. If you are looking to get something working fast, you could look into AccuracyAwareTuning offered by Intel’s Neural Compressor which automatically finds the optimal configuration for quantization based on your pre-defined evaluation criteria.
- Depending on the type of model you want to compress: If you’re interested in mobile deployment of CNNs, you could look into techniques offered by Sony’s Model Optimization Toolkit. You would need to do a little bit of research to determine which one will work best for you. For LLMs, you can look into LLM-QAT and QLORA. LLM-QAT provides an innovative solution for quantizing LLMs by leveraging generations produced by a pretrained model, achieving data-free distillation. With their method, you can quantize not only weights and activations but also the (K-V) cache into 4 bits with minimal accuracy drop. QLORA falls under the category of quantization-aware Parameter Efficient Fine Tuning (PEFT) Techniques. QLORA enables large models to undergo fine-tuning on a single GPU. QLORA is integrated with BitsandBytes and can be used with HuggingFace directly. For LLM-QAT, use the author's GitHub repo. The following figure should help you get a high-level view of LLM quantization connections.

Conversely, If you don’t have the time and resources for QAT: You could look into the Post Training Quantization features offered by some of these tools.
- Depending on your level of expertise:If you have the time for experimentation, you could again first experiment with the QuantAnalyzer to determine sensitive layers and then look into the specialised BatchNorm folding, CrossLayer Equalization or AdaRound algorithms supported by AIMET.
If you’re a novice user and are trying to get something working fast, you can experiment with AIMETs autotuning quantization API which will try to automatically find the optimal parameters for your model. INC’s AccuracyAwareTuning also works for PTQ so you could experiment with that as well.
- Depending on the type of model you want to compress: If you’re working with CNNs and are interested in deployment on mobile devices, you can take a look at GPTQ, PowerofTwo or EPTQ offered by Sony’s Model Optimization Toolkit or DeFora and BNN offered by NNI. You can also experiment with Pytorch’s PTQ directly - you can look at the table in the Pytorch Built In Quantization section for some guidelines. For LLMs, if you don’t want a significant accuracy loss you could go with 8-bit quantization with BitsandBytes or SmoothQuant. SmoothQuant quantizes both weights and activations so you can expect more reduction in memory when compared with BitsandBytes but this will come at the cost of some accuracy loss. If you’re not too strict on accuracy and have limited memory on your device, you can consider GPTQ, AWQ or SqueezeLLM. These techniques can quantize the model to 4 bits, 3 bits or even 2 bits in the case of GPTQ. GPTQ and AWQ rely on a calibration dataset which can be a hindrance for some users because of lengthy quantization times. In this case, the user can look into SqueezeLLM which doesn’t require a calibration dataset and might offer better accuracy as well because of the fact that it splits the weights into sparse and dense and only quantizes the dense component (Note that, because of this division, SqueezeLLM does require more memory as well).
Conclusion
This concludes our tour of quantization tools and techniques. As you can see there are many solutions available that are better suited for different kinds of user profiles and use cases. We hope this post helped you get a high level understanding of which tools are best to be used in which scenarios! Stay tuned for the next post of our model compression series!
More Reads










Wish Your LLM Deployment Was
Faster, Cheaper and Simpler?
Use the Unify API to send your prompts to the best LLM endpoints and get your LLM applications flying