




Compilers: Talking to The Hardware

One of the key drivers behind the rapid expansion in machine learning growth is the technological progress made in the development of application-specific compilers.
While architectural discoveries allow for the design of mathematically efficient models, compilers are what perform the conversion of the human-readable code of frontend languages used to develop the models, into the binary code which a machine can understand. This compilation process enables machine learning models to run faster, more accurately, and on a wider range of devices, making them more accessible and easier to integrate into practical applications.
In this blog post, we will give an overview of the machine learning compiler landscape, highlighting the unique features of existing solutions. We will discuss how these compilers are helping to overcome some of the biggest challenges facing machine learning, such as performance, scalability, and deployment, and how they are enabling new use cases and applications that were previously not possible.
Our aim through this post is to help you appreciate the role compilers in the machine learning lifecycle, and make sense of the current state of the landscape to understand how to make the most out of this technology when running your models. For this purpose, we’ll begin with getting a general understanding on how compilers work and introducing popular general-purpose compilers, before diving into machine learning-specific compilers and their applications.
A General View on Compilers
As we’ve briefly mentioned, compilers are responsible for the conversion of high-level human code into low-level machine code. Making sure this conversion remains efficient is crucial to ensure performance remains optimal when running a given piece of code on a machine.
At a high level, the compilation process typically consists of 6 stages:
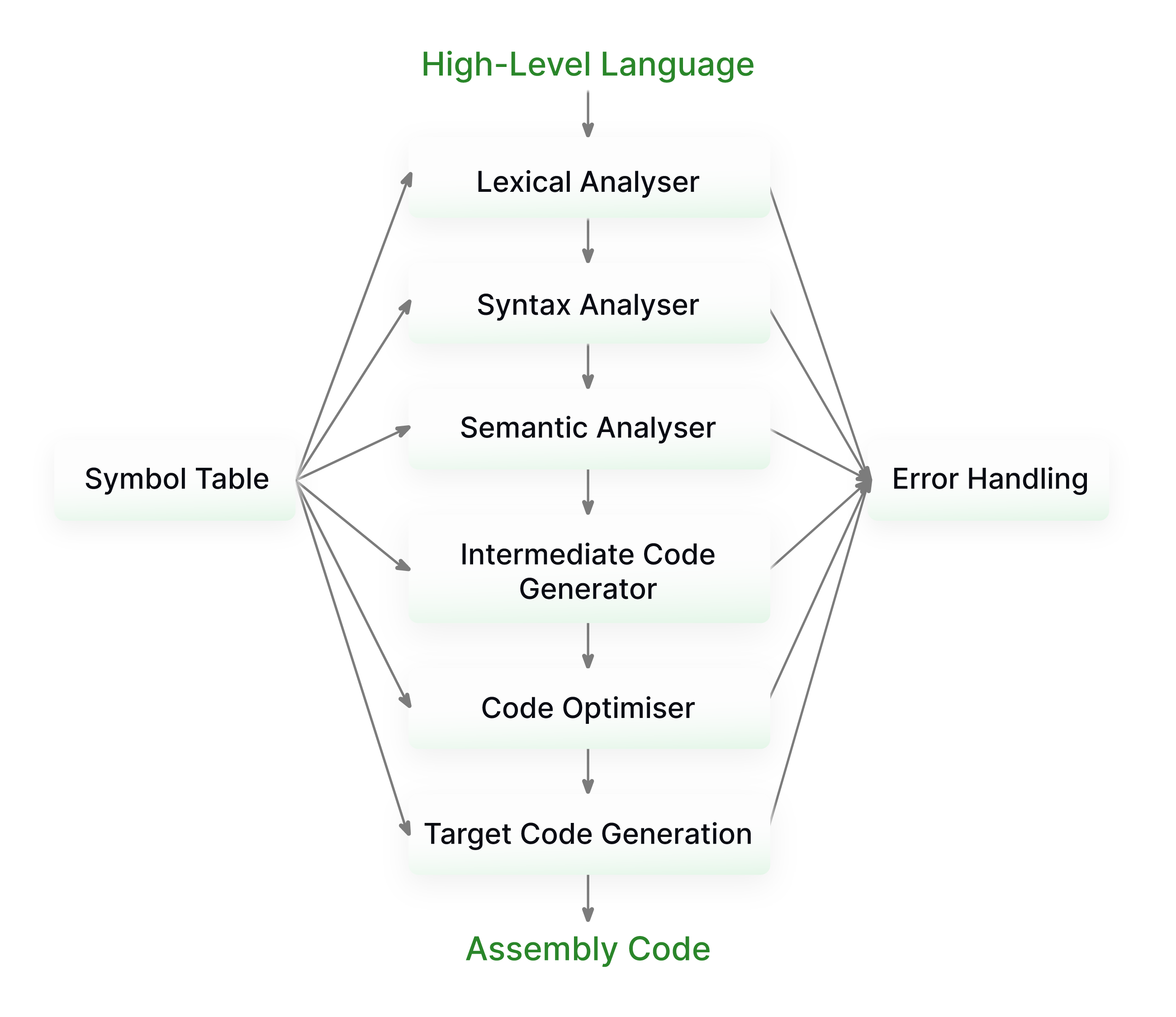
- Lexical Analysis: This stage consists of the conversion of the raw text of the input program into lexical tokens, in the case of natural language, these would be your nouns, verbs, adjectives, etc. In programming languages, these include categories such as keywords, identifiers and operators.
- Syntactic Analysis: In this stage, the compiler parses the sequence of tokens (often referred to as a token stream) produced by the lexer and organizes them into a syntactic tree.
- Semantic Analysis: The final “frontend” phase, involves checking the program for context-sensitive errors, some examples being type checking and the analysis of inheritance relationships.
- Intermediate Code Generation: This is the stage in which the code from the frontend language is converted into an intermediate representation (IR), which is a language in and of itself, the syntax of which usually looks something like a mix between frontend languages and assembly.
- Optimization: Taking the IR generated by the last step as input, the compiler now performs a series of optimization passes ranging from more general tasks such as the elimination of dead code (DCE) or common subexpressions (CSE), to more domain-specific logic like operator fusion and tiling, which are two of the most important optimizations in the context of deep learning.
- Target Code Generation: This final stage takes the hardware-agnostic, optimized IR code as input and converts it into the hardware-specific, machine code of the architecture which is being targeted, i.e. x86 for Intel CPUs or PTX for Nvidia GPUs.
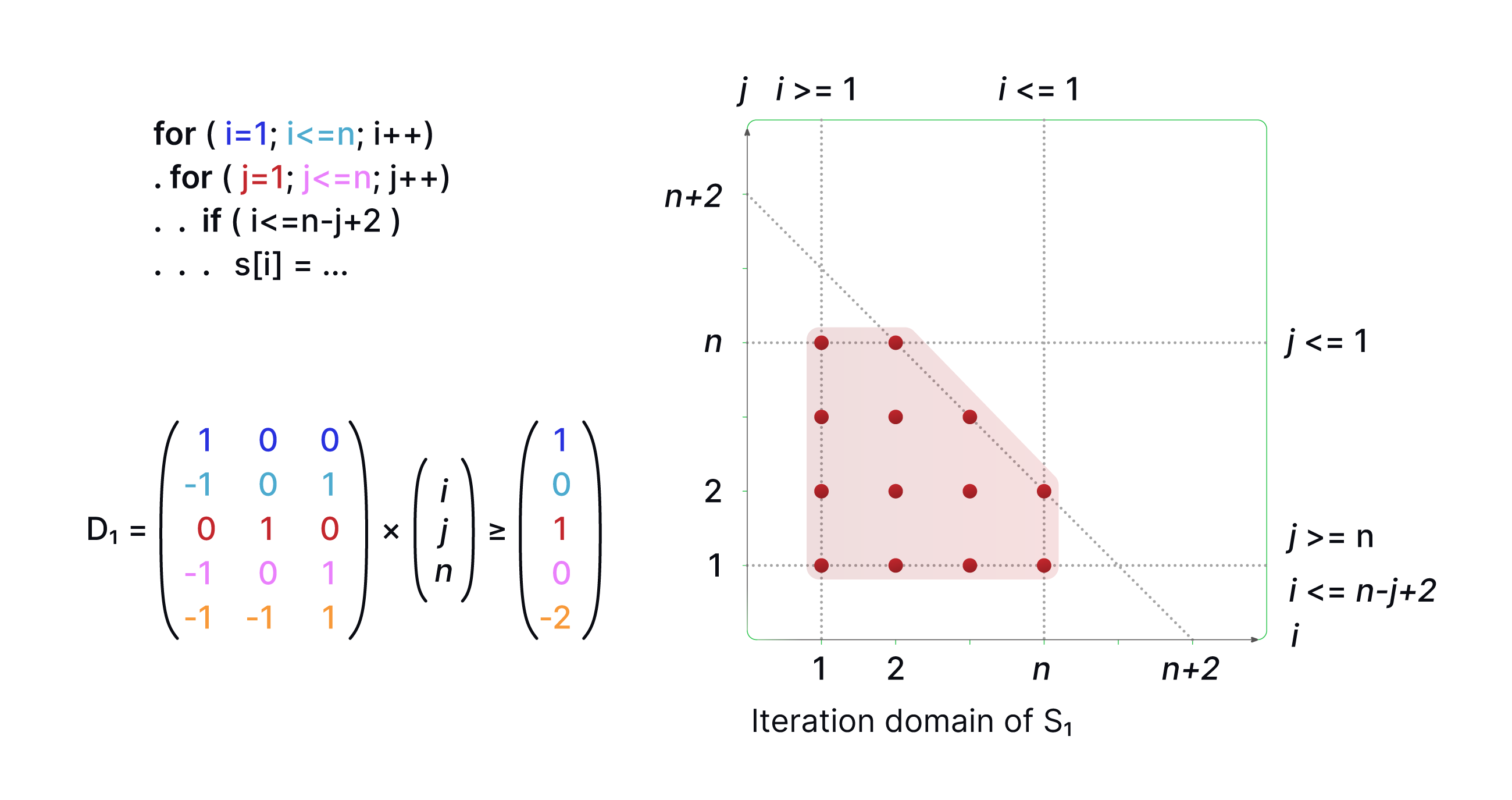
A fundamental concept in the compiler space which we will see consistently pop up across our survey is the polyhedral model. The polyhedral model in compilers is a mathematical approach used for optimizing loop nests in high-level programming. In this model, loops are represented as geometric shapes (polyhedra) in a high-dimensional space, where each point in the shape corresponds to an individual iteration of the loop. The edges and faces of the polyhedron represent the relationships and dependencies between different iterations. This representation allows the compiler to perform sophisticated transformations on the loops, such as tiling, fusion, or parallelization, by manipulating the shapes in this abstract space.
These transformations can significantly improve the performance of the program, particularly for applications with complex loop structures and large amounts of data processing (like deep learning!). The polyhedral model excels at capturing and optimizing the parallelism and locality in loop nests, making it a powerful tool for optimizing the core operations found in a neural network, such as matrix multiplication.
Let's take a brief look at some commonly used, general-purpose compilers which are still relevant to the field of deep learning, before diving into some more domain-specific examples.
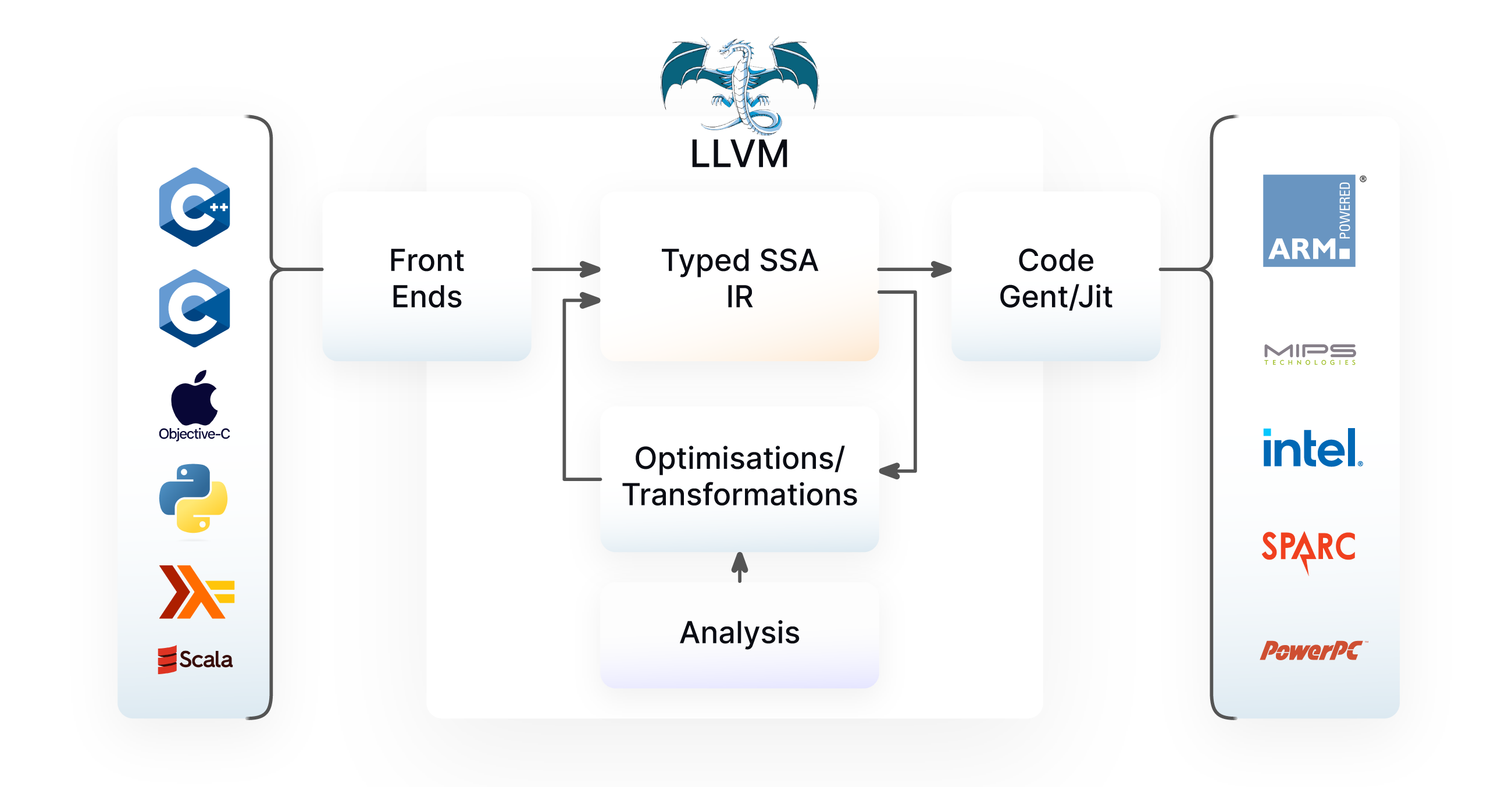
LLVM: LLVM, which stands for Low-Level Virtual Machine, is a collection of modular and reusable compiler toolchain technologies. It's designed to optimize and compile programming languages, whether high-level or low-level, into efficient machine code that can be executed on various target architectures. LLVM’s key innovation was creating a common infrastructure for the lower half of the compilation stack, starting with the LLVM IR and going all the way down to target-specific codegen. LLVM is open-source and has become a fundamental infrastructure for a wide range of programming languages and tools such C, C++ and MLIR, to name just a few.
GCC : GNU Compiler Collection (GCC) is a set of compilers for various programming languages, primarily C, C++, and Fortran. GCC is an open-source software package that provides the necessary tools to compile, optimize, and generate executable code from source code written in these languages.
NVCC : Based on the LLVM toolchain, NVIDIA's CUDA Compiler (NVCC) allows developers to create or extend programming languages with support for GPU acceleration using the Nvidia Compiler SDK. The notable difference here compared to baseline LLVM is that CUDA compiler source code is modified with a parallel thread execution backend, enabling full support of NVIDIA GPUs.
Halide: Halide is a C++-based, domain-specific language (DSL) for writing high-performance image and array processing code. Its key innovation was the introduction of a scheduling language model, which decouples the definition of an algorithm from the scheduling logic detailing how it is to be executed, this provides a convenient separation of concerns, allowing the programmer to experiment with discovering which implementation of an algorithm delivers the best performance without having to rewrite the algorithm itself. This same model was later adopted by TVM for deep-learning tasks.
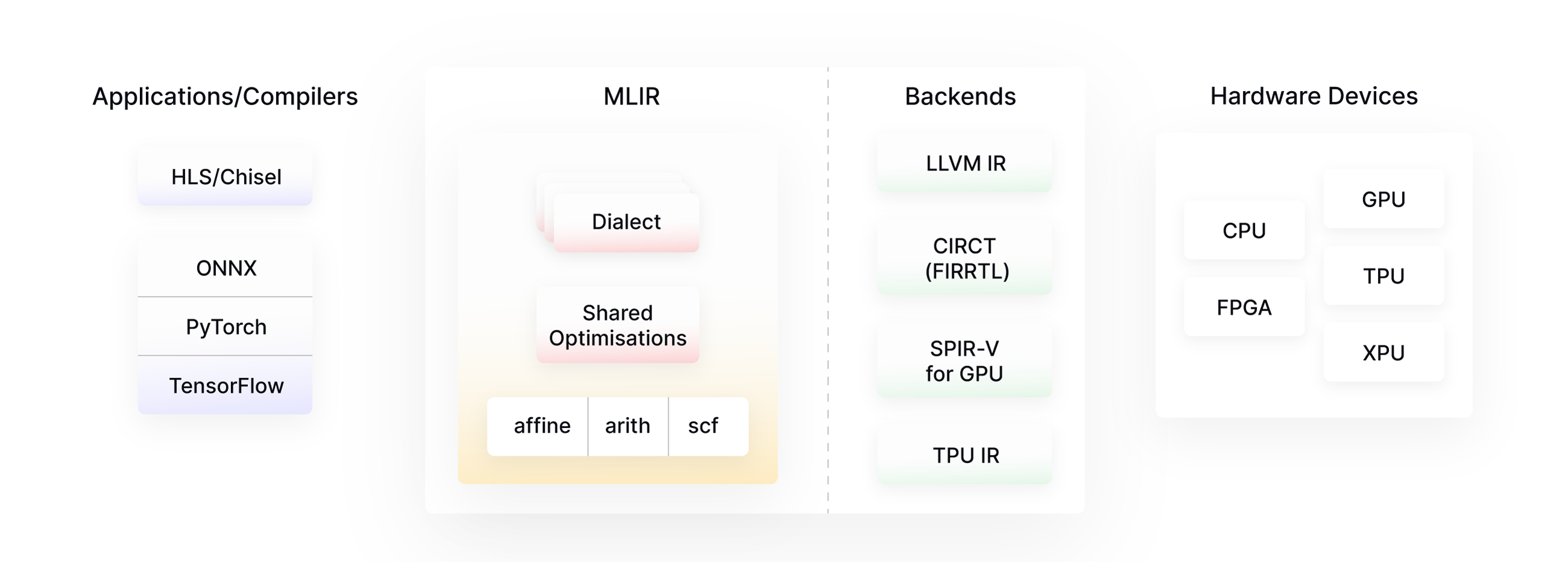
MLIR: MLIR, which stands for Multi-Level Intermediate Representation, is a compiler infrastructure, originally developed at Google but now maintained by the LLVM foundation, which is designed to be a flexible and extensible framework for representing and optimizing programs and data structures across various stages of compilation and execution, particularly in the context of high-performance computing, machine learning, and domain-specific languages.
One of the core contributions of MLIR is its unified IR syntax which can support this wide range of representations, from high-level tensor ops with value semantics all the way down to assembly instructions, it does this through the usage of dialects, which, as the name suggests, are essentially sub-languages for these different levels of abstraction. Some examples of dialects include the affine dialect for polyhedral transformations, the arith dialect for elementary arithmetic operations, and the scf dialect for structured control flow.
On the hardware-specific side, there are unique dialects for different architectures like x86 and Arm, as well as for standardized device representations such as SPIR-V for GPUs. Though initially born out of the XLA project with deep learning applications in mind, MLIR is in fact a general purpose compiler infrastructure which can be used for a wide range of domain-specific tasks such as quantum computing and even circuit design.
Diving into Deep Learning Compilers
Having laid the foundations of the compilation process and looked at the building-block technology, we will now take a look at the rich world of deep learning compilers, taking a loosely chronological approach to the order in which we present them.
To hearken back to our definition of the 6 major phases of compilation presented above, it’s important to note that these domain-specific compilers usually focus purely on the latter 3 steps, as the first 3 are already handled by the native compiler of our frontend language, which in this case is usually Python. Having already dealt with these initial phases of token generation as well as syntactic and semantic analysis, the inputs passed into these compilers are usually computation graphs derived from high-level frameworks such as PyTorch, which are then translated into an intermediate representation often taking the form of a directed acyclic graph (DAG) consisting of the fundamental mathematical operations (often referred to as Ops) which make up a neural network.
Open Source Compilers
The major open-source compilers used in the field as of today that are also actively maintained include:
TensorRT
TensorRT is a high-performance deep-learning inference library developed by NVIDIA. It is designed to optimize and accelerate the inference of deep neural networks for production deployment on NVIDIA GPUs. TensorRT is commonly used in applications that require real-time, low-latency, and high-throughput processing of deep learning models.
Given the DAG of the model as an input, TensorRT creates its own DAG. Then it applies optimizations like operation fusion in kernel level and memory rearrangements to speed up the inference. It also eliminates redundant operations that either don’t contribute to the output or don’t change the final result when removed. For example, if there are two successive reshape operations that cancel each other, both will be dropped during the optimization process. It supports dynamic shapes for inputs when models are simple like CNNs or MLPs. Internally it uses pre-compiled CUDA kernels from linear algebra and deep learning libraries like cuBLAS and cuDNN.
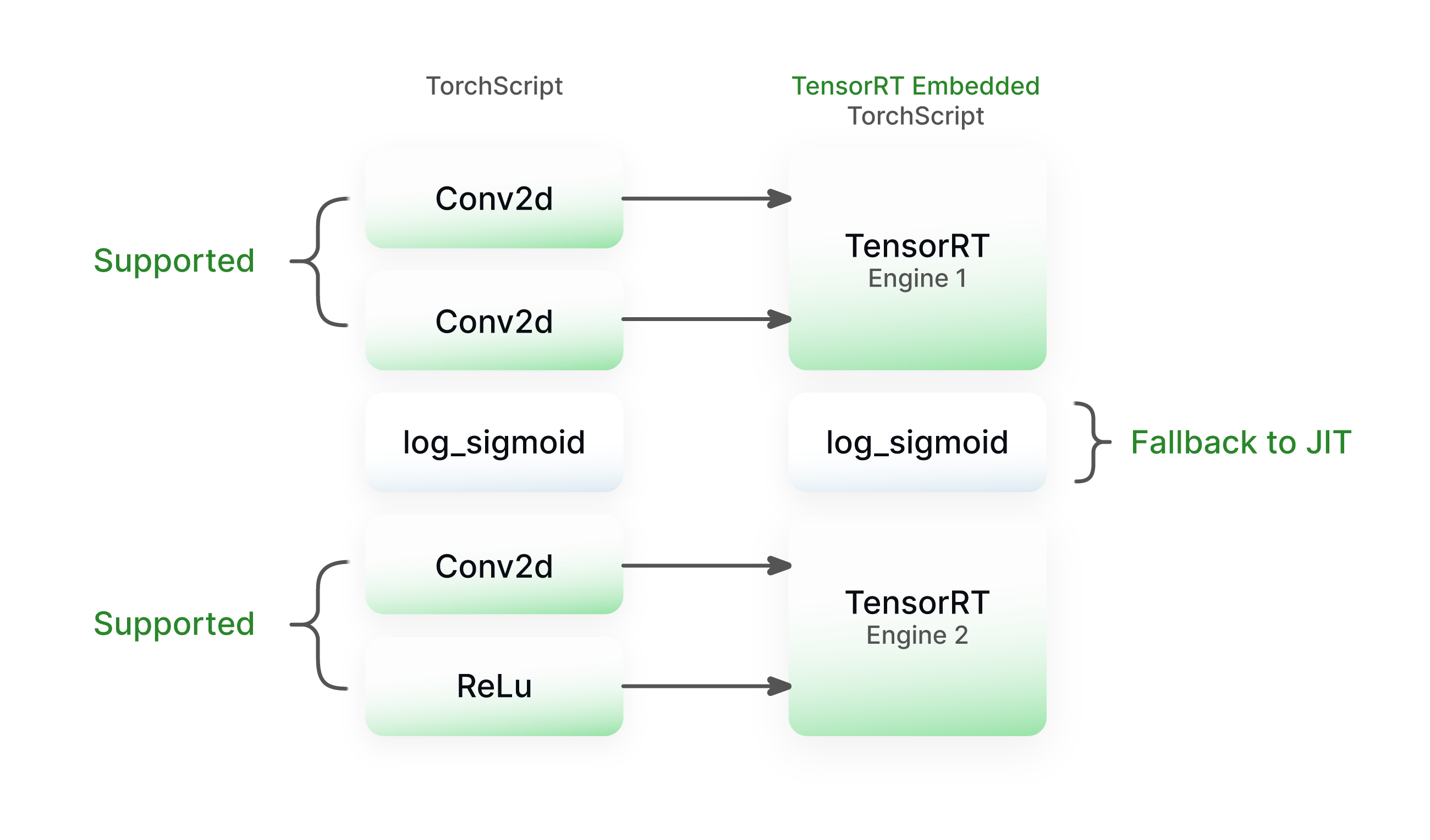
In Pytorch, the model is first converted into TorchScript or TorchFX and then parts of the computational graph that are convertible to TensorRT are replaced with their TensorRT equivalents. As a result, the model will be a hybrid of TorchScript and TensorRT nodes, offering high-level flexibility as in the figure below. More Torch to TensorRT op converters could be added to make the graph fully convertible. The downside of this is that the cost of maintaining a huge library of op converters increases.
OpenXLA
OpenXLA or XLA, which stands for Accelerated Linear Algebra, is a domain-specific compiler, developed by Google, designed to optimize and accelerate the execution of the core linear algebra operations commonly used in machine learning and other numerical computing tasks.
XLA is often associated with TensorFlow, where it is used to improve the performance of TensorFlow models, and more recently, combined with an autograd engine, forms the backbone of JAX. The primary goal of XLA is to take high-level mathematical operations defined in the frontend framework and compile them into optimized low-level code that can be executed on various hardware accelerators, such as GPUs and TPU, which XLA was specifically designed to support.
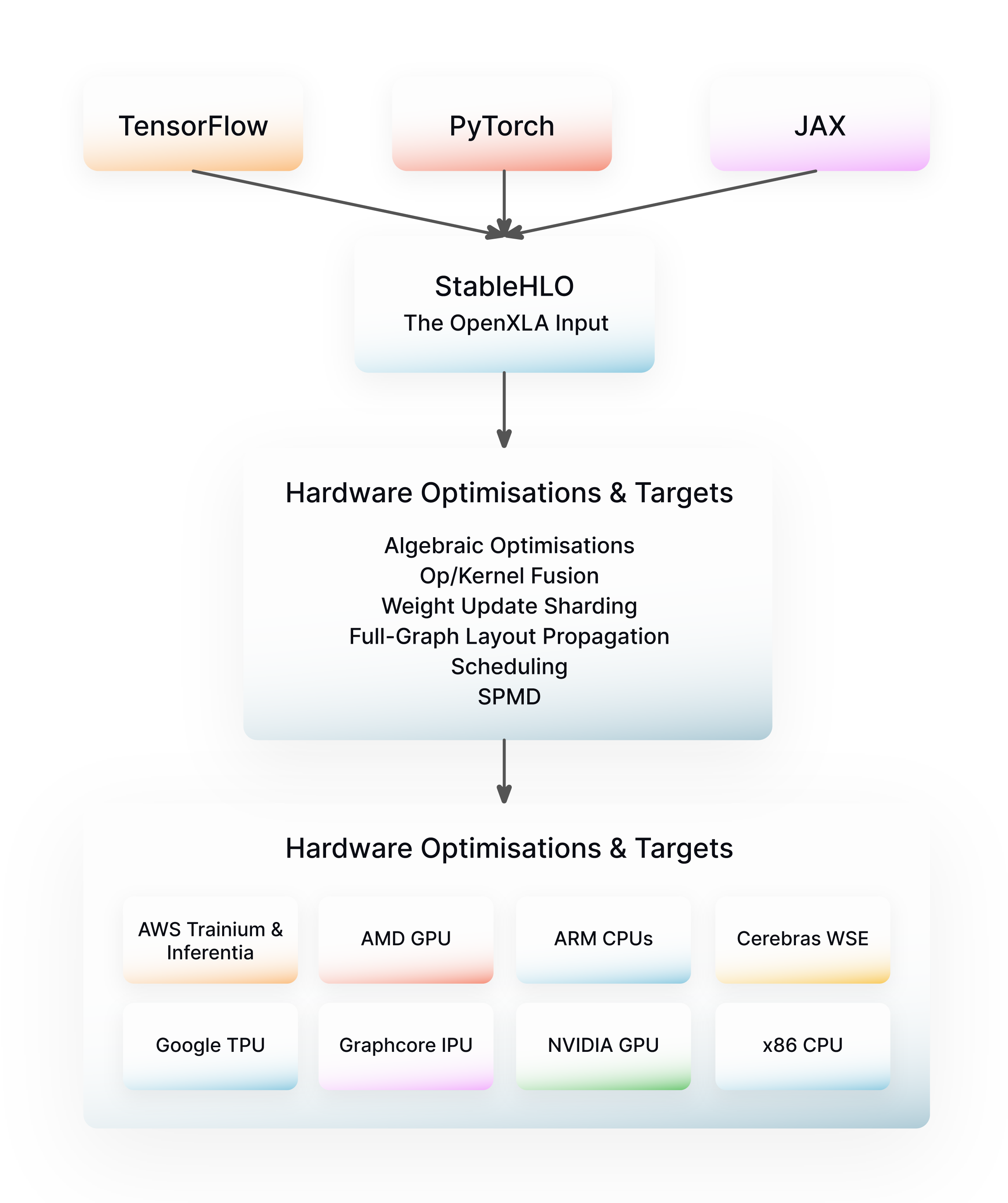
The XLA pipeline consists of decomposing the input program into a fixed set of high-level operations (HLO), then performing a series of target-independent optimization passes, such as weight update sharding or kernel fusion, on this HLO IR, before offloading to device-specific libraries like CuDNN for Nvidia GPUs or Eigen for CPUs, for handling hardware-dependent optimizations.
Though originally built with a unique IR syntax, over the years XLA has gradually integrated MLIR into its compilation pipeline, providing the ability to both import and export MLIR modules from its corresponding HLO dialects (MHLO, LHLO) as well as adding optimization passes written fully in MLIR. In 2022, Google fully open-sourced XLA, moving it to a new repository independent of Tensorflow, and created the OpenXLA foundation to continue its support and broaden the ecosystem with the development of new tools such as StableHLO, a backwards-compatible MLIR dialect for representing HLO ops, and IREE, which we cover in more detail later on.
TVM
TVM, which stands for Tensor Virtual Machine, is an end-to-end compiler stack for deep learning, aiming to provide a comprehensive set of optimizations for a wide variety of hardware backends, including custom accelerators. It uses the same scheduling language model as that which was first introduced by Halide, allowing an algorithm to be defined separately from its scheduling logic. Unlike most DL compilers, which tend to be graph-based, TVM’s Relay IR is a functional language with full support for common programming constructs such as conditionals and loops, giving it better support for more complex, dynamic models. TVM generates its own low-level, hardware-specific code for a diverse set of backends and utilizes an ML-based cost model called AutoTVM which adapts and improves codegen based on continuous data collection. Recently it has been added as a backend of torch.compile.
Glow
Glow, which is an abbreviation for Graph-Lowering, consists of a strongly typed, two-phase Intermediate Representation, splitting optimizations up between the high level and low level respectively. Glow’s compilation pipeline seeks to solve the issue of targeting a large number of opcodes for different hardware backends by decomposing all higher level operations into a finite set of simpler, more universally supported ones, hence eliminating the need to implement any new layer or activation as a custom op for every hardware backend.
Like TVM and IREE, Glow generates its own machine-specific code rather than offloading to third-party compute primitive libraries. The low-level side of its IR uses an instruction-based, address-only format, allowing it to excel at memory-related optimizations such as memory-allocation and instruction scheduling, however, due to the strong typing, Glow does not support dynamic shapes such as some of the other compilers (XLA, TVM, IREE) do. Despite being developed by Meta directly under the PyTorch umbrella, direct support for Glow has yet to have been added to the PyTorch API, as any PyTorch code must first be converted to ONNX before being passed in.
OpenAI-Triton
Triton is an open-source programming language and compiler designed for the purpose of expressing and compiling tiled computations within neural networks into highly efficient machine code. Triton demonstrates how just a few control-flow and data-handling extensions to LLVM-IR could enable various optimization routes for a neural network.
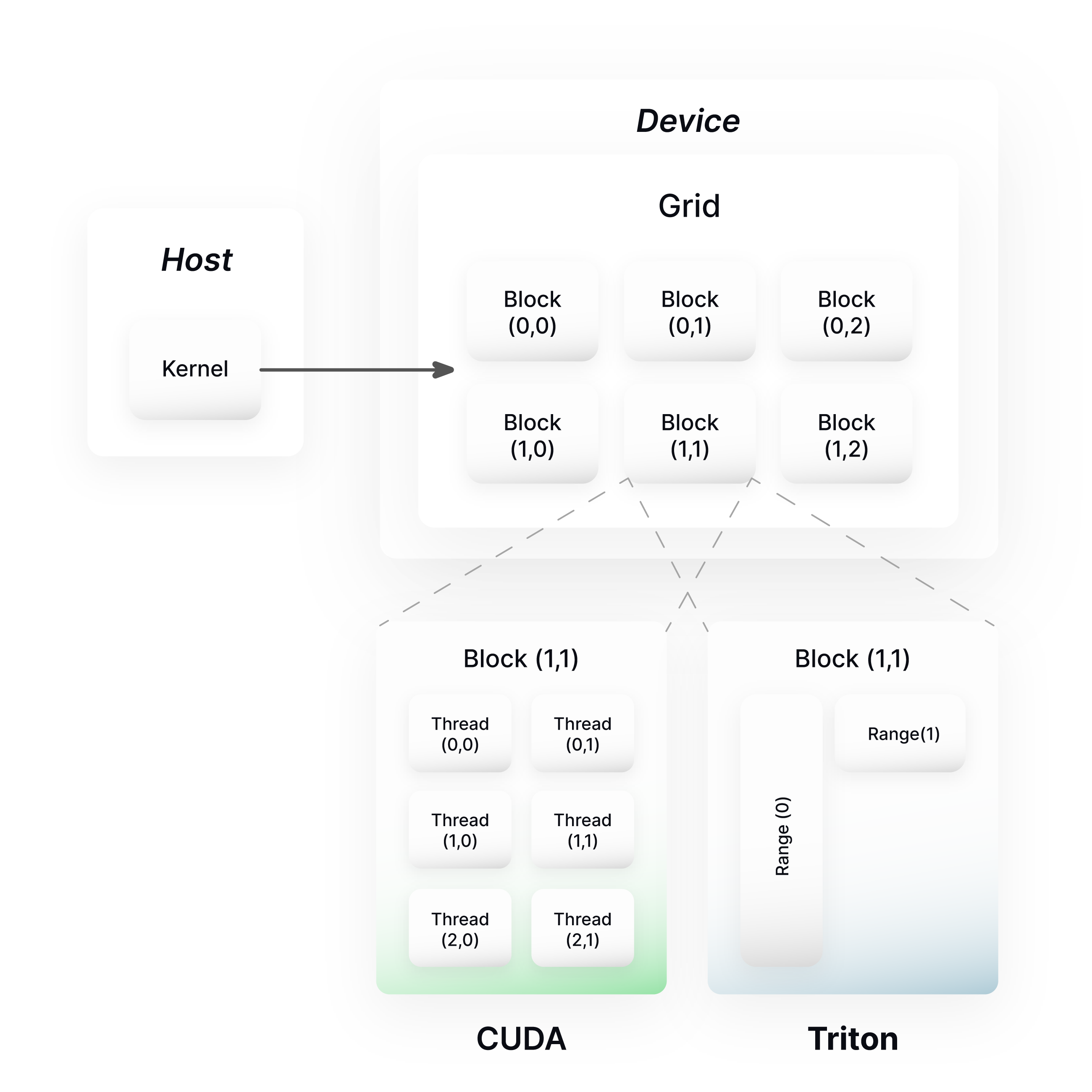
Designed to provide the same kernel-level control as CUDA, Triton introduces a new, block-based rather than thread-based programming model for GPUs, offering a higher, more user-friendly abstraction. The compilation pipeline consists of writing a GPU kernel in a simple, Python or C-like format, which is then lowered into the originally LLVM-based, now MLIR-based, Triton-IR, Triton-JIT then performs a series of platform-independent, followed by platform-specific, tile-level optimization passes before generating the final LLVM/PTX code.
Triton's auto-generated kernels have been shown to match or even outperform the performance of handwritten cuDNN and cuBLAS ones, however, currently Triton only supports Nvidia GPUs. It has recently become the main building block behind the most efficient Torch backend for GPUs, called TorchInductor, showcasing Triton’s utility.
IREE
IREE, which stands for Intermediate Representation Execution Environment, is an MLIR-based compiler and runtime stack specifically designed to be able to scale down to meet the tight constraints of mobile and edge deployment, while still retaining the ability to scale up to more traditional, large-scale settings like datacenters and compute clusters.
IREE provides an end-to-end compilation pipeline, ranging from high-level optimizations similar to XLA, all the way down to a Hardware Abstraction Layer (HAL) which generates device-specific code. IREE has taken much inspiration from, and integrates seamlessly with Vulkan, a popular cross-platform GPU API which uses SPIR-V, a standardized binary intermediate language for GPUs. One of IREE’s greatest strengths is the high degree of modularity that it provides due to its utilization of a different MLIR dialect for each layer of abstraction, from tensor-based input dialects such as StableHLO, TOSA and Torch-MLIR, to internal dialects handling low-level tasks such as dataflow analysis, partitioning and scheduling.
IREE stands as being the most robust end-to-end compiler/runtime stack built fully around MLIR, providing a concrete example of its utility.
SHARK
SHARK is a high-performance ML compiler and runtime, developed by Nod.ai, a performance-focused AI startup recently acquired by AMD, specifically for accelerating PyTorch code. It is built using components from IREE and Torch-MLIR, an MLIR dialect for representing PyTorch operations, as well as an in-house, ML-based autotuner.
SHARK has shown a number of promising features and results, including TorchDynamo integration, a hardware-agnostic implementation of the seminal Flash-Attention algorithm, and even exceeding the performance of OpenAI Triton while running Flash-Attention 2 on an A100 GPU.
Hidet
CentML open-sourced a deep learning compiler for GPU called Hidet. DNN compilers like Halide, TVM and Ansor decouple computation definitions and scheduling of computation. Moreover, scheduling is automated by the compiler and the user has limited control over the scheduling process. This works well on loop-related optimizations and misses finer-level optimizations like double buffering, use of TensorCores and multi-stage asynchronous prefetching. Hidet addresses this limitation by proposing a task-mapping programming paradigm where the user can define task assignment to workers (i.e. threads) and their order. And post-scheduling fusion allows to fuse surrounding operations into a single kernel.
Closed Source Compilers
Closed source compilers also make up an integral part of the compilers landscape, we mention a few notable such compilers in what follows.
PolyBlocks
Though yet to have been fully released, PolyBlocks is a promising MLIR-based compiler engine which utilizes a modular, block-like structure of compiler passes, making it highly extensible and reusable for a variety of hardware architectures. As the name suggests, it specializes in the use of polyhedral optimization techniques, utilizing MLIR’s affine dialect, as well as leveraging high-dimensional data spaces for compilation, supporting both Just-in-Time (JIT) and Ahead-of-Time (AOT) compilation and performing full codegen, making it fully independent of any third-party vendor libraries. Its benchmarks have shown performance which exceeds that of hand-written Nvidia libraries such as CuBLAS, CuDNN and TensorRT on A100 GPUs.
Mojo
Mojo is not just a compiler, but rather an entirely new programming language recently introduced by Chris Latner’s (of LLVM fame) company, Modular. Offering a syntax nearly identical to that of Python, Mojo seeks to combine Python’s ease of use with the low-level control and runtime efficiency which languages like C and C++ provide. Being a superset of Python, Mojo provides full interoperability with existing packages in the Python ecosystem such as pandas and matplotlib.
Mojo also introduces a slew of new features which Python lacks, including type checking, ownership, SIMD (Single Instruction Multiple Data) programming and even autotuning features to finetune parameters for optimal performance on one’s target hardware. Built on top of MLIR, Mojo also allows full extensibility and interoperability with any existing tools in the MLIR ecosystem, and can even be thought of as a programming language for MLIR, as it provides the ability to write custom MLIR code in a more user-friendly, Pythonic syntax.
Along with this new language, Modular also provides an AI inference engine (written using Mojo kernels) which existing models written in PyTorch or Tensorflow can be easily ported to for efficient inference. Currently, Mojo supports all CPU architectures and is planning on supporting GPUs and custom accelerators in the near future.
Artemis/EvoML
Created by a startup called TurinTech, Artemis and EvoML both provide unique, ML-based solutions to the problem of code optimization. Artemis utilizes a combination of pre-trained LLMs and traditional code analysis techniques to provide insights into the underlying inefficiencies and areas for improvement in your code base, as well as leveraging active learning so that the user can create custom LLMs finetuned on the specifics of their codebase.
EvoML on the other hand takes the generative approach, using an LLM of the user’s choice combined with some proprietary ML techniques to aid in data cleaning and generating optimal code.
Conclusion
Through our post, we gave an overview of the machine learning compiler landscape. With that said, we haven’t introduced all existing tools and instead focused the discussion on the most widely used. We invite curious readers to check our database where we continuously collect various model deployment optimisation tools, including compilers, that you can consult to get a more comprehensive outlook of the space.
As we have seen from our brief survey, the landscape of ML compilers is vast and deeply fragmented. However, with more and more compilers gradually beginning to adopt technologies like MLIR which seek to unify compiler infrastructure, perhaps in a few years, we will see a more standardized and uniform pipeline for both ML compilers and DSLs in general, much like how LLVM had previously unified the lower half of the compilation stack across many languages.
As handwritten techniques like Flash-Attention often still dominate in achieving optimal performance, compiler engineers are proactively looking for new ways to dynamically generate such algorithms through the use of Ml-based methods like autotuning algorithms and even fully ML-driven compilation.
Existing toolchains like TVM and Mojo already incorporate basic ML methods for autotuning certain parameters, while many researchers and even some companies like TurinTech seek to further integrate deep learning technologies like LLMs into the compilation pipeline. How far such approaches can automate the compilation process and whether or not humans may ever be fully removed from the loop are fascinating questions whose answers only time will tell.
More Reads










Wish Your LLM Deployment Was
Faster, Cheaper and Simpler?
Use the Unify API to send your prompts to the best LLM endpoints and get your LLM applications flying